
2024年4月
2024-04-11
多模态检索
- 调研了相关算法
- 基本框架
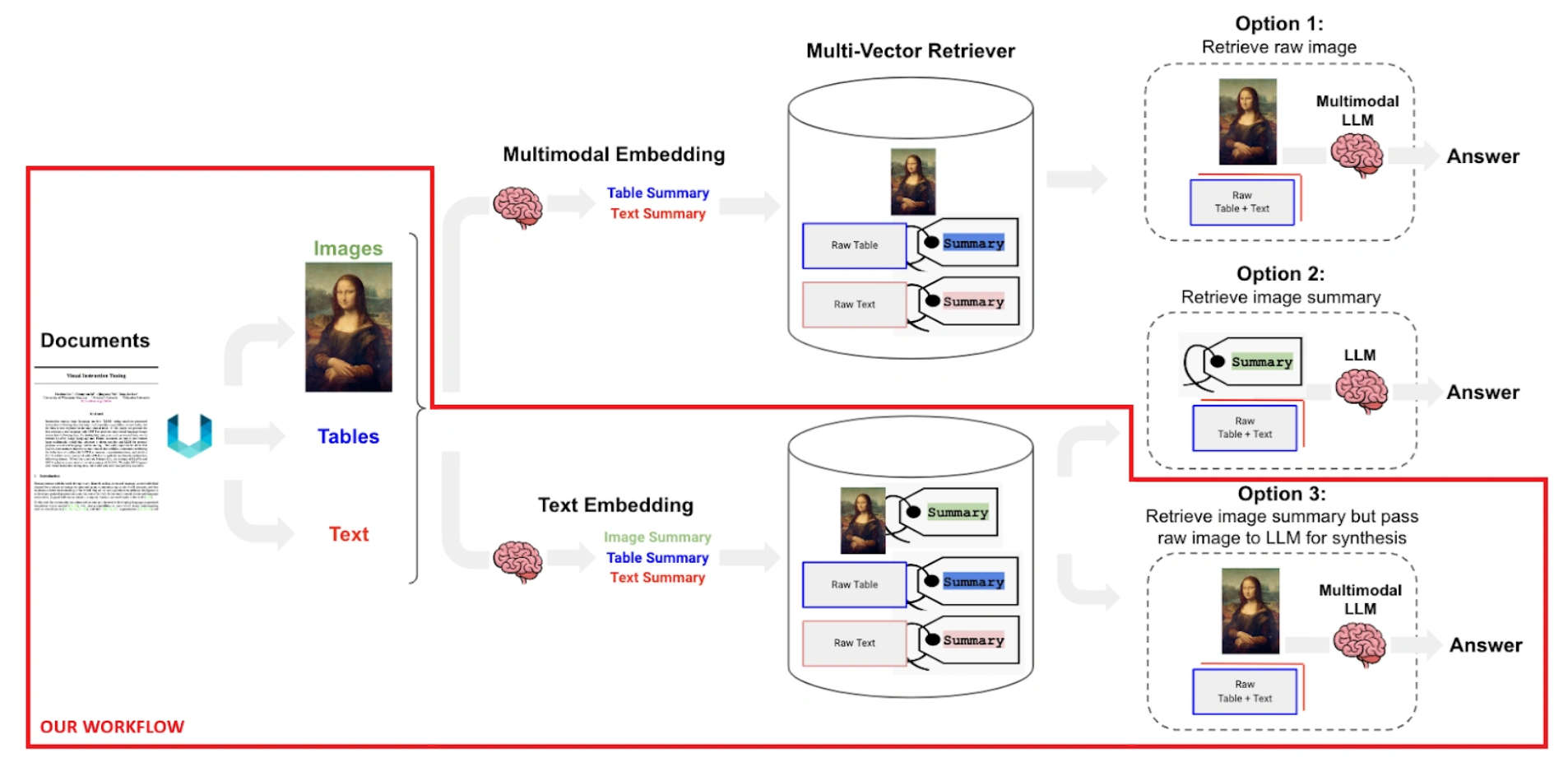
- 流程图
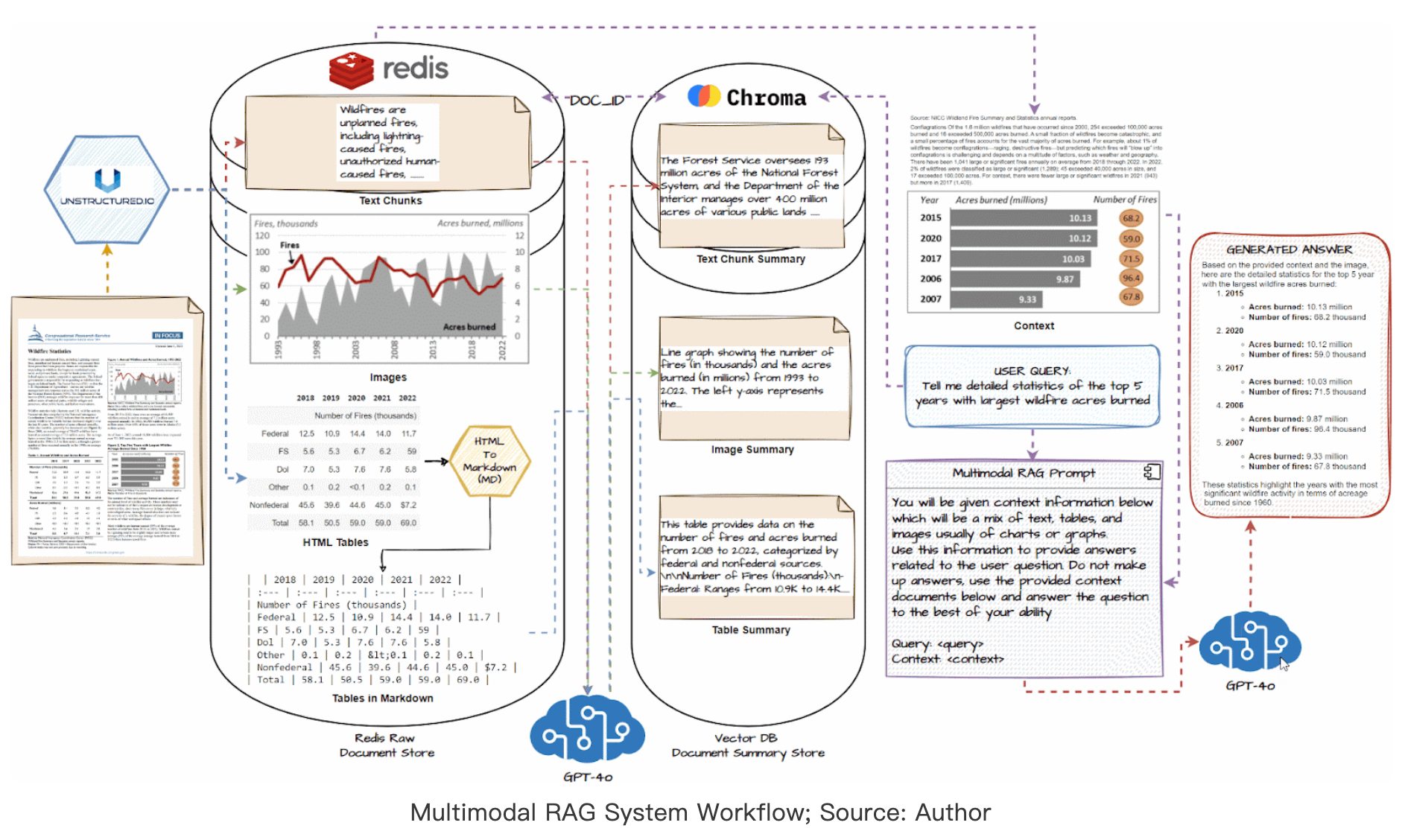
- 调研了多模态检索的三种主要方案:
- 方案1:基于多模态向量检索
- 将图表和文本分别编码为向量
- 使用向量相似度进行检索
- 优点:实现简单,检索速度快
- 缺点:可能丢失细粒度语义信息
- 方案2:基于跨模态对齐
- 学习图文之间的对齐关系
- 使用注意力机制进行特征融合
- 优点:可以捕获更细粒度的语义对应
- 缺点:计算开销较大
- 方案3:基于混合检索策略
- 结合向量检索和跨模态对齐
- 先粗排后精排的两阶段方案
- 优点:平衡了效率和效果
- 缺点:系统复杂度增加
- 方案1:基于多模态向量检索
- 分析了各方案的适用场景:
- 方案1适合大规模快速检索
- 方案2适合对检索精度要求高的场景
- 方案3适合实际应用部署(采用该方案)
- 运行了基线模型
- 实验结果:
- BLEU: xx.xx
- METEOR: xx.xx
- 发现的问题:
- 在处理长句子时性能下降明显
- 视觉特征提取可能需要优化
周会汇报准备
- 整理了本周实验结果
- 准备了演示 demo
- 需要补充:
- 添加定量分析
- 准备失败案例分析
备忘录
待办事项
- 准备下周组会报告
- 完成实验代码重构
- 整理文献综述
研究想法
- 想法1:将强化学习应用到对话生成中
- 想法2:探索多模态预训练的新方法
有用的资源
- 数据集列表:…
- 常用工具:…
- 参考论文:…
2025-04-14
deepseek-r1显存占用
| 模块 | 显存占用估算(FP8) | 说明 |
|---|---|---|
| 🧠 模型权重本体 | ~640 GB | 672B 参数 × 1 Byte(FP8 编码) + 结构 buffer |
| 🗃️ 上下文缓存(prompt embeddings) | ~140 GB | 长 prompt 或系统提示信息存储区 |
| 📊 KV Cache(多轮对话缓存) | 200–300 GB | 注意力缓存,随 token 数增长;影响最大 |
| ✅ 总计推理负载 | ~1.0–1.1 TB | 真实推理状态下所需 GPU 显存峰值 |
实测数据
| 部署规模 | 并发数 | 速度 |
|---|---|---|
| 单台8卡H200 | 128 | 11 tokens/s |
| 单台8卡H200 | 256 | 7 tokens/s |
| 双台8卡H200 | 300-350 | 7-10 tokens/s |
支持用户总数约为:2000人
2025-4-15
监控助手
- 完成Mac电脑上调用摄像头和录音
- 尝试调用本地模型
2025-4-16
服务器空间不足解决方案
- 扩容
sudo lvextend -L +20G /dev/ubuntu-vg/ubuntu-lv sudo resize2fs /dev/ubuntu-vg/ubuntu-lv
2025-5-16~2025-6-16
天迹原型搭建
- 检测图
- 完成自动生成检测内容功能和视频流实时检测

2025-7-7
服务器连接本地代理
export https_proxy=http://192.168.0.175:7890 http_proxy=http://192.168.0.175:7890 all_proxy=socks5://192.168.0.175:7890
2025-8-15
服务器转发到本地屏幕
/opt/TurboVNC/bin/vncserver :1
### 本地端口设置
192.169.0.200:5901